

해시 알고리즘 쉽게 배우기
배열 사용
 배열의 좋은 점 : 인덱스의 위치를 사용해서 데이터를 찾을 때 O(1)로 매우 빠른 특징을 가지고 있다. O(1)
배열의 좋은 점 : 인덱스의 위치를 사용해서 데이터를 찾을 때 O(1)로 매우 빠른 특징을 가지고 있다. O(1)
배열의 안좋은 점: 배열을 검색할 때 배열에 있는 데이터를 모두 비교해야 함 O(n)
Index 사용
데이터의 값을 인덱스 번호로 검색을 함으로써 O(n)의 검색 연산을 O(1)의 검색 연산으로 바꾼다

문제
만약에 데이터가 0~99까지 늘어난다면 인덱스도 0~99까지 사용해야한다
크기 100의 배열이 필요함
예를들어 [1, 2, 6, 99] 의 값을 넣으면
[null, 1, 2, null, null, null, 6, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, null, null, null, null, null,
null, null, null, null, null, null, null, null, 99]
한계
매우 빠른 속도로 검색은 가능하나 O(1), 메모리 공간이 너무 많이 낭비된다
⟪나머지 연산 (Hash Index)⟫
배열의 크기 (CAPACITY) = 10
- 1 % 10 = 1
- 2 % 10 = 2
- 5 % 10 = 5
- 14 % 10 = 4
- 99 % 10 = 9

데이터 저장할 때
- 해시 인덱스를 먼저 구한 후, 해시 인덱스 위치에 데이터 저장
- arr[hashIndex] = value
- 값을 저장하는데 O(1)로 빠른 성능 → 해시 인덱스 생성 O(1) + 해시 인덱스를 사용해 배열에 값 저장 O(1)
데이터 조회할 때
- 해시 인덱스를 구하고, 배열에 해시 인덱스를 대입해서 값을 조회
- int value = arr[hashIndex]
-
배열의 인덱스를 사용해서 하나의 값을 찾는데 O(1)로 빠른 성능 제공
-
*코드 구현*public class Set { static final int CAPACITY = 10; public static void main(String[] args) { //{1, 2, 5, 8, 14, 99} System.out.println("hashIndex(1) = " + hashIndex(1)); System.out.println("hashIndex(3) = " + hashIndex(3)); System.out.println("hashIndex(5) = " + hashIndex(5)); System.out.println("hashIndex(14) = " + hashIndex(14)); System.out.println("hashIndex(99) = " + hashIndex(99)); Integer[] inputArray = new Integer[CAPACITY]; add(inputArray, 1); add(inputArray, 3); add(inputArray, 5); add(inputArray, 16); add(inputArray, 99); System.out.println("inputArray = " + Arrays.toString(inputArray)); //검색 int searchValue = 99; int hashIndex = hashIndex(searchValue); System.out.println("searchValue hashIndex = " + hashIndex); Integer result = inputArray[hashIndex]; System.out.println(result); } static void add(Integer[] inputArray, int value) { int hashIndex = hashIndex(value); inputArray[hashIndex] = value; } static int hashIndex(int value) { return value % CAPACITY; } }-
결과
hashIndex(1) = 1 hashIndex(2) = 3 hashIndex(5) = 5 hashIndex(14) = 4 hashIndex(99) = 9 inputArray = [null, 1, null, 3, null, 5, 16, null, null, 99] searchValue hashIndex = 9 99
-

문제
만약 같은 해시 인덱스가 나오면?
1 % 10 = 1
11 % 10 = 1
해시 충돌을 방지 해야함
⟪해시 충돌 방지⟫
CAPACITY를 값의 입력 범위만큼 키우면 안되나?
→ 충돌은 발생 안하겠지만, 메모리 낭비 겁나 심함
해결

-
설명
데이터를 등록할 때 먼저 해시 인덱스(hashIndex)를 구한다. 해시 인덱스로 배열의 인덱스를 찾는다. 배열에는 연결 리스트가 들어있다.
해시 인덱스를 통해 바구니들 사이에서 바구니인 연결 리스트를 하나 찾은 것이다. 셋은 중복된 값을 저장하지 않는다. 따라서 바구니에 값을 저장하기 전에
contains()를 사용해서 중복 여부를 확인한다. 만약 바구니에 같은 데이터가 없다면 데이터를 저장한다.

-
설명
해시 인덱스로 배열의 인덱스를 찾는다. 여기에는 연결 리스트가 들어있다. 연결 리스트의
bucket.contains(searchValue)메서드를 사용해서 찾는 데이터가 있는지 확인한다.연결 리스트의
contains()는 모든 항목을 다 순회하기 때문에 O(n)의 성능이다. 하지만 해시 충돌이 발생하지 않으면 데이터가 1개만 들어있기 때문에 O(1)의 성능을 제공한다. -
9번 인덱스를 찾는다 → 값을 하나씩 비교한다
😵💫BUT, 최악의 경우
- 9, 19, 29, 99를 저장할 때 → 모두 해시 인덱스 9가 됨
- 저장한 데이터의 수 만큼 값을 반복해서 비교 → O(n)의 성능
-
*코드 예시*public class Set { static final int CAPACITY = 10; public static void main(String[] args) { //{1, 2, 5, 99 ,9} // 배열안에 LinkedList를 넣어준다 -> LinkedList는 가끔 충돌남 LinkedList<Integer>[] buckets = new LinkedList[CAPACITY]; for (int i = 0; i < CAPACITY; i++) { buckets[i] = new LinkedList<>(); } add(buckets, 1); add(buckets, 2); add(buckets, 5); add(buckets, 99); add(buckets, 9); //중복 System.out.println("buckets = " + Arrays.toString(buckets)); //검색 int searchValue = 9; boolean contains = contains(buckets, searchValue); System.out.println("buckets.contains(" + searchValue + ") = " + contains); } public static void add(LinkedList<Integer>[] buckets, int value) { int hashIndex = hashIndex(value); LinkedList<Integer> bucket = buckets[hashIndex]; // O(1) if (!bucket.contains(value)) { // O(n) bucket.add(value); } } public static boolean contains(LinkedList<Integer>[] buckets, int searchValue) { int hashIndex = hashIndex(searchValue); LinkedList<Integer> bucket = buckets[hashIndex]; // O(1) return bucket.contains(searchValue); // O(n) } static int hashIndex(int value) { return value % CAPACITY; } }-
결과
buckets = [[], [1], [2], [], [], [5], [], [], [], [99, 9]] buckets.contains(9) = true
-
충돌이 발생하면 데이터를 추가하거나 조회할 때, 연결 리스트 내부에서 O(n)의 추가 연산을 해야 해서 성능이 떨어짐.
🤗GOOD, 현실
-
정리
입력 값의 범위가 넓어도 실제 모든 값이 들어오지는 않기 때문에 배열의 크기를 제한하고, 나머지 연산을 통해 메모리가 낭비되는 문제도 해결할 수 있다. 해시 인덱스를 사용해서 O(1)의 성능으로 데이터를 저장하고, O(1)의 성능으로 데이터를 조회할 수 있게 되었다. 덕분에 자료 구조의 조회 속도를 비약적으로 향상할 수 있게 되었다.
HashCode()
HashCode() 메서드를 통해서 문자를 기반으로 고유한 숫자를 만들 수 있다 →
해시 코드
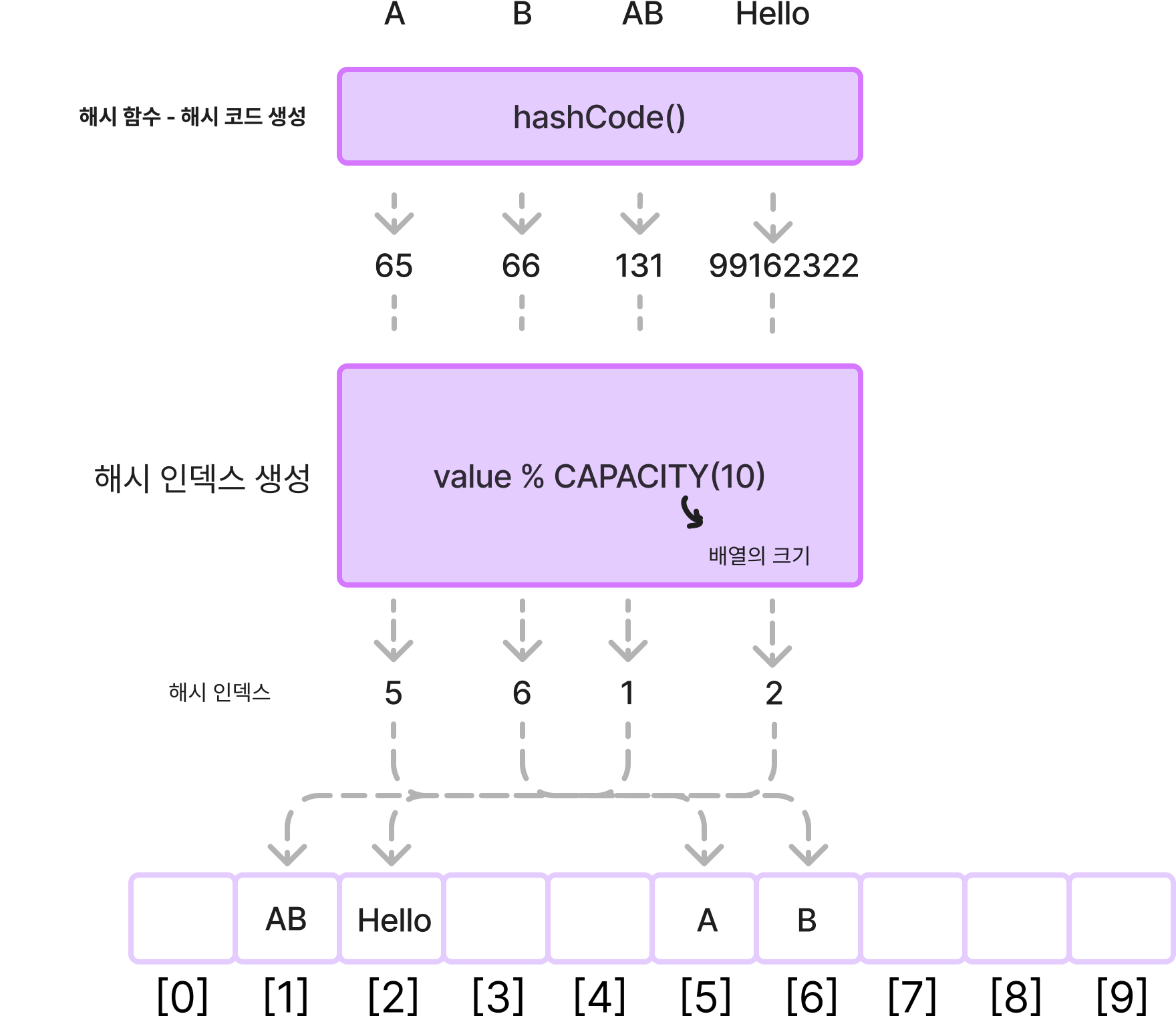
- 문자열을 해시 코드로 변경 → 고유한 정수 값 =
해시 코드 - 해시 코드를 사용해서 해시 인덱스 생성
-
정리
문자 데이터를 사용할 때도, 해시 함수를 사용해서 정수 기반의 해시 코드로 변환한 덕분에, 해시 인덱스를 사용할 수 있게 되었다. 따라서 문자의 경우에도 해시 인덱스를 통해 빠르게 저장하고 조회할 수 있다.
참고
https://night-knight.tistory.com/entry/🚀-파이썬의-set-함수와-list-함수의-in-함수-사용-시-시간복잡도
https://velog.io/@bada308/알고리즘-해시Hash
https://adjh54.tistory.com/490
https://velog.io/@mooh2jj/Hash의-개념-및-설명