

JVM
반갑습니다. 지난시간 RDBMS에 이어 이번에는 JVM을 주제로 기술세미나 발표를 한 정지용 입니다.
[1. 개요]
우리가 자바를 공부하고, 스프링을 쓰고 있지만
기업의 니즈 때문에 라는 이유를 빼고, 왜 자바를 쓰는지 생각해보신적 있으신가요?
제가 생각하는 자바를 쓰는 이유는 객체지향이라는 개념적인 부분도 있겠지만
우리가 도커를 사용하듯 OS에 종속이 최소인 기술적 장점도 있기 때문이라 생각합니다.
이번 시간에는 JVM이란 무엇인지 일부 알아보는 시간을 가져보고자 합니다.
[2. JVM란?]

JVM은 이름 그대로 자바를 가상의 환경에서 작동시켜주는 소프트웨어입니다.
WORA 원칙을 가지고 있어 한번 작성하면 어디서든 동일하게 실행 할 수 있도록 설계되었습니다.
JVM의 요소는 아래와 같은 항목들이 존재합니다.
이 항목들을 10분이라는 짧은 시간동안 전부 알기엔 부족하므로, 초록색 글씨의 2가지만 살펴보고자 합니다.
[3. C vs JAVA]
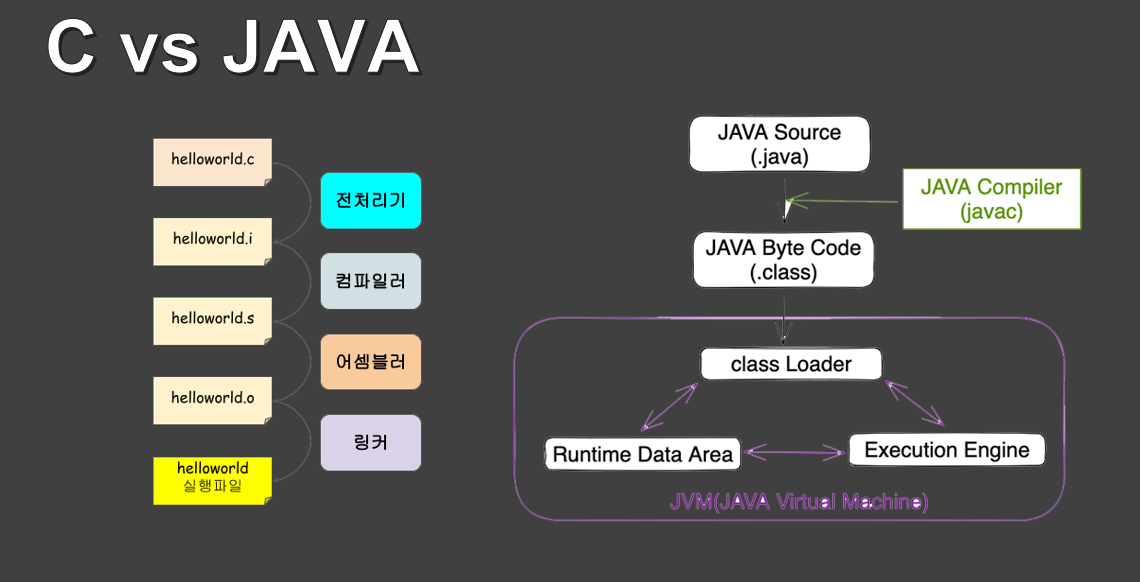
이 과정을 알기 위해선 불가피하게 C와 JAVA의 컴파일 과정 차이를 알아야 합니다.
C언어는 이미지의 왼쪽처럼 다양한 과정을 통해 결국 기계어로 변환하여 CPU의 명령어 세트에 맞춰지고,
이로 인해 다른 CPU에서 동일한 코드를 실행하려면 그에 맞는 재컴파일을 해야합니다.
이번에 맥OS 환경에서 구축 된 도커 이미지를 vultr에 도커 컨테이너로 올려보셨다면
아키텍쳐가 달라서 실행이 불가하다는 이슈를 접하셨을텐데, 매우 유사한 시나리오 입니다.
자바는 그에 비해 우리가 작성한 소스 코드를 바이트 코드로 변환합니다.
JVM은 이 바이트 코드를 OS에 맞는 네이티브 코드로 변환하고 실행합니다.
이 역할을 해주는 담당자가 JVM의 요소중 누구냐면 바로 다음장에 나오는 Jit Compiler 입니다.
[4. Jit Compiler]
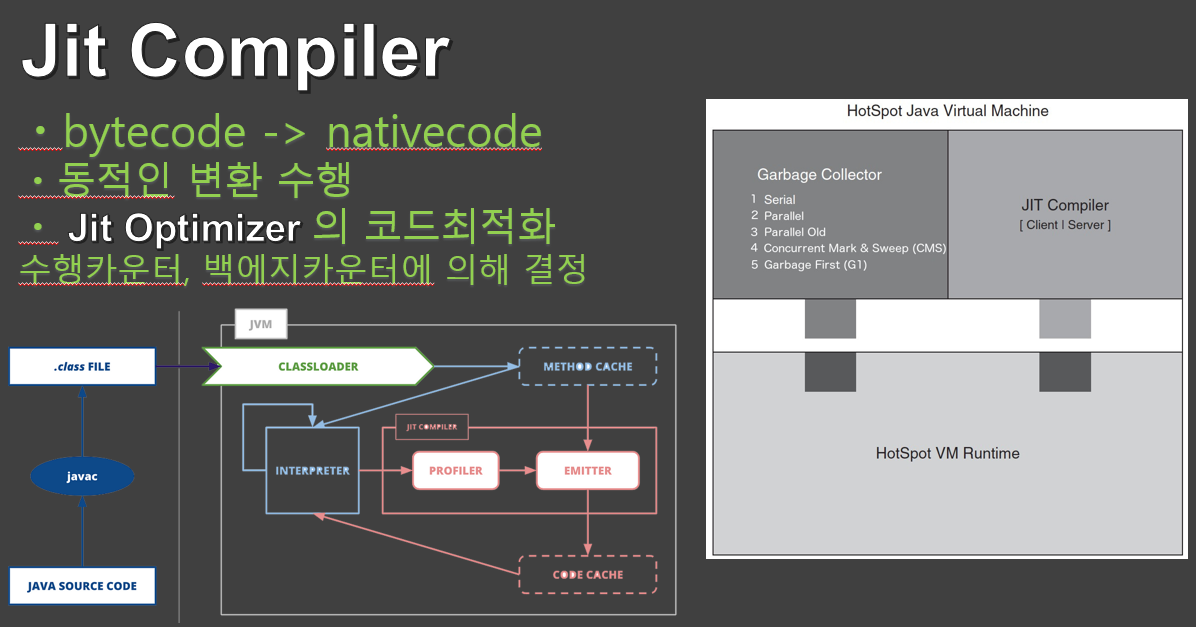
오른쪽 이미지를 보시면 HotSpot VM 라는 아키텍처 이미지가 있는데,
간단히 말하자면 Hotspot VM은 JVM을 실행하는 런처와 스레드 관리, JNI 관리 등을 하는 곳이고
테트리스 맞추듯 GC와 컴파일러를 끼워맞춰 사용합니다.
C 컴파일러는 한번 컴파일을 요구하면 바이트 코드까지 한번에 만들어 버리는데,
자바는 실제 애플리케이션 실행에 필요한 네이티브 코드를 만드는 책임을 JVM에게 넘겼습니다.
그렇기 때문에 JVM은 항상 바이트 코드로 시작하여 동적으로 네이티브 코드로 바뀝니다.
모든 코드는 이미지에 보이는 인터프리터에 의해 어떤 코드들이 있는지 인지는 되지만
실질적인 컴파일은 해당 코드가 많이 사용되는 우선순위에 따라 결정됩니다.
그 결정을 담당하는건 옵티마이저가 하고,
수행카운터와 백에지카운터라는 두개의 카운터에 의해 우선순위가 결정됩니다.
쉽게 풀어서 말하자면 수행카운터는 메서드가 시작 할 때마다 증가하는 값이고
백에지 카운터는 메서드가 얼마나 반복적으로 수행되는지를 체크하는 값입니다.
그렇게 결정된 우선순위에 따라 큐에 컴파일요청을 쌓게되고, 컴파일러는 순서대로 컴파일을 합니다.
JVM 옵션에서 백에지 카운터 수치를 조정 할 순 있지만
VM튜닝을 하는 것이 아닌이상 보편적으로 손댈일은 잘 없지않을까 싶습니다.
이 덕분에 자바의 JVM은 한번 작성한 코드를 어디서든 실행 할 수 있는 WORA를 준수하게 됩니다.
[5. JVM의 종류]

이제 JIT 컴파일러의 최적화 과정을 말씀드릴까 하는데
이 JVM이라는 것도 목적에 따라 종류가 매우 다양합니다.
첫번째 이 Jrockit은 밑의 핫스팟이 쓰이기전에 나온 초기버전입니다.
두번째 핫스팟 JVM은 요즘 자바에서 쓰이는 표준 JVM이라 이해하시면 되겠습니다.
세번째는 IBM에서 개발한 것으로 경량화되어 임베디드나 클라우드 환경에서 쓰이고 이클립스 재단에서 관리하고 있습니다.
그랄VM은 자바뿐만 아니라 자바스크립트, 파이썬, 루비처럼 다른 언어도 지원하는 것이 특징입니다.
중국어처럼 보이는 아줄 징 JVM은 놀랍게도 미국회사이고, GC 성능이 강조된 고성능 JVM인 것이 특징입니다.
네이버 클라우드 플랫폼도 이 아줄 JVm을 사용 및 서비스합니다.
종류가 이만큼 많다는건? 내부 구조도 다 다르다는 이야기입니다.
우리는 그중 첫번째 J락킷의 컴파일러로 알아보려고 합니다.
[6. Jrockit의 최적화 - 구조]
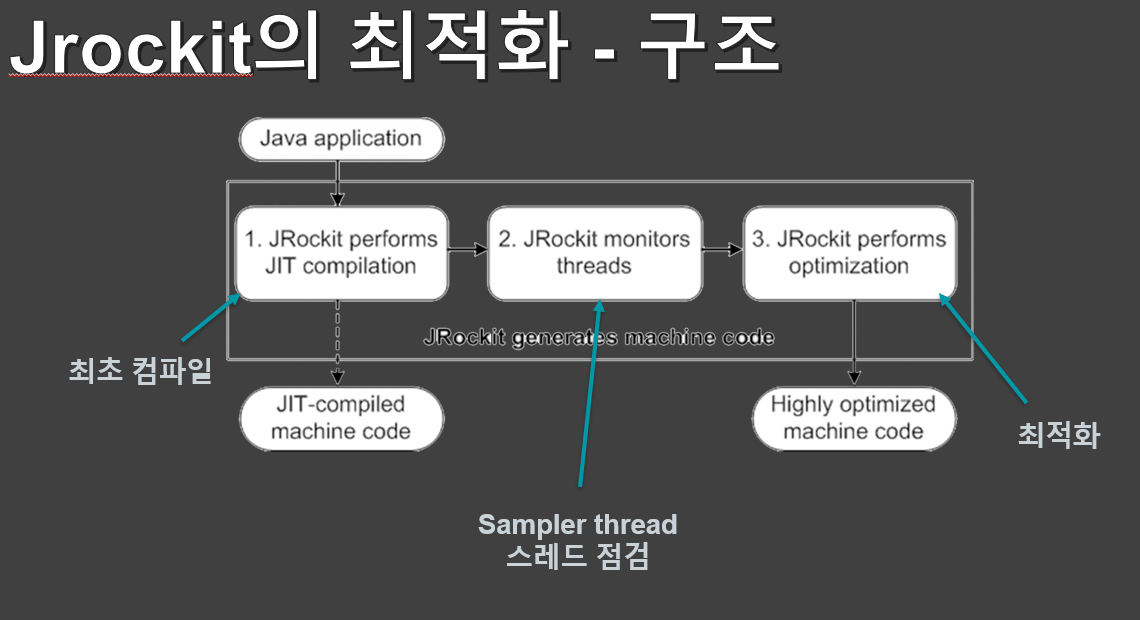
첫 부팅때는 모든 메서드에 대해 최초 컴파일을 거친다면 오버헤드로 인해 느릴 수 있지만
앞서 설명한 JIT 옵티마이저, 컴파일러로 인해 시작은 느려도 판단에 따라 최적화가 이뤄지므로
지속적으로 수행 할 수록 더 빠른 처리가 이루어집니다.
두번째 스레드 모니터는 샘플러스레드가 어떤 스레드들이 동작중인지, 수행내역을 관리합니다.
이를 통해 어떤 메서드가 많이 쓰이는가 최적화 대상을 탐색합니다.
마지막으로 샘플러 스레드가 식별한 대상을 최적화하며
수행중인 어플리케이션에 영향을 주지 않습니다.
[6. Jrockit의 최적화 - 코드]

첫번째와 같이 Class A에서 Class B를 사용하고 void foo()를 통해 y, z에 b.get()을 대입하여 sum을 하는 코드가 있다고 가정해봅시다.
- final method의 inline 처리를 합니다. b.get()을 b.value로 바꾸어 메서드콜로 인한 성능저하를 개선합니다.
- z,y 값이 동일하므로 z에 y를 할당하여 불필요한 호출 부하를 제거합니다.
- z와 y가 동일하므로 불필요 변수 z를 y로 변경합니다.
- 3의 과정으로 y=y가 되었으므로 데드코드를 삭제합니다.
이러한 최적화 과정을 통해 우리가 코드를 작성하면서 가독성을 살리기위해
같은 변수를 여러번 사용, 대입하여도 성능에 지장을 최소화 하도록 하게됩니다.
마치 우리가 코드 리팩토링을 하는 과정과 비슷하죠?
이렇게해서 JVM의 OWRA의 의미가 무엇인지, 바이트코드는 어떤 과정으로 컴파일 되는지
컴파일에 쓰이는 많은 JVM중 가장 기초적인 Jrockit의 최적화 과정을 살펴보았습니다. 감사합니다.