

Spring Data JPA를 사용할 때, @Transactional을 직접 선언하지 않아도 트랜잭션이 자동으로 적용되는 것을 확인할 수 있다.
어떻게 자동으로 적용되는 것일까? 그리고 이 과정에서 프록시는 어떤 역할을 할까?
이번 글에서는 Spring Data JPA의 트랜잭션 관리 원리를 프록시(proxy)와 관계지어 알아보자.
1. JPA Respository에서 @Transactional 없이도 트랜잭션이 동작하는 이유
Spring Data JPA에서 JpaRepository를 상속받으면 기본적으로 제공되는 CRUD 메서드(save(), findById(), delete() 등등)는 트랜잭션이 자동으로 적용된다.
//FileMetadataRepository.java
public interface FileMetadataRepository extends JpaRepository<FileMetadata, Long> {
//구현한 것이 없다.
}
우리가 직접 @Transactional을 선언하지 않아도 트랜잭션이 동작하는 이유는 무엇일까?
이를 이해하려면 JpaRepository가 상속하는 인터페이스 계층도부터 살펴볼 필요가 있다.
1.1 JpaRepository 계층 구조
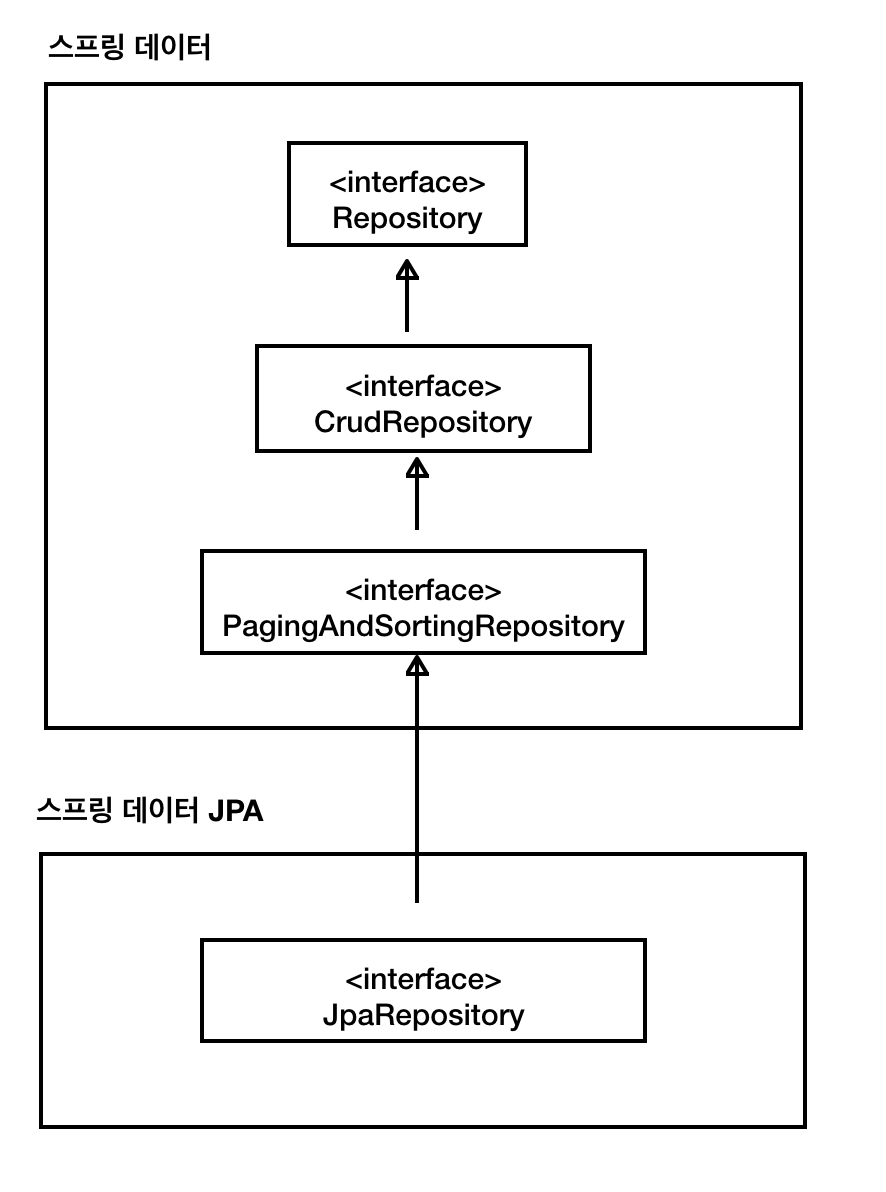
Spring Data JPA의 JpaRespository는 여러 개의 인터페이스를 계층적으로 상속 받는다.
이 인터페이스들은 추상적인 정의만 제공할뿐 실제 구현체는 없다.
그럼 구현체도 없는데 어떻게 트랜잭션이 적용된 것인가? 라는 의문을 가질 수 있는데
JPA의 트랜잭션 처리가 @Transactional없이도 동작하는 이유는 Spring Data JPA가 제공하는 기본 구현체 덕분이다.
1.2 SimpleJpaRepository 내부의 트랜잭션 적용
SimpleJpaRepository는 Spring Data JPA에서 제공하는 기본 JPA 리포지토리 구현체이다.
즉, JpaRepository 인터페이스를 구현하는 기본 클래스이며 개발자가 직접 구현하지 않아도 기본적인 기능들을 제공해준다.
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (this.entityInformation.isNew(entity)) {
this.entityManager.persist(entity);
return entity;
} else {
return this.entityManager.merge(entity);
}
}
SimpleJpaRepository의 save() 메서드를 보면 다음과 같이 @Transactional이 선언되어 있다.
즉, Spring이 SimpleJpaRepository를 자동으로 구현체로 사용(주입)하면서 트랜잭션을 적용해준다.
1.3 SimpleJpaRepository의 주요 특징
1.기본 CRUD 기능 자동 제공
- 별도의 구현 없이 JpaRepository를 상속하는 것만으로 기본적인 CRUD 기능을 사용할 수 있다.
2.EntityManager를 사용하여 JPA 쿼리 실행
- 내부적으로 JPA의 EntityManager 를 사용하여 데이터를 조회하고 저장한다.
3.트랜잭션 관리 지원
- Spring의
@Transactional을 활용하여 쓰기 연산은 트랜잭션을 적용하고, 읽기 연산은 기본적으로 트랜잭션 없이 동작한다.(읽기 전용 트랜잭션을 적용하려면@Transactional(readOnly=true)필요)
4.동적 쿼리 지원 (Specification)
- JpaSpecificationExecutor를 함께 사용하면, 동적으로 조건을 조합하여 검색할 수 있다.
2. 프록시와 트랜잭션의 관계
Spring의 @Transactional이 제대로 동작하려면 프록시(proxy) 가 필요하다.
Spring은 AOP(Aspect-Oriented Programming) 기법을 활용하여 프록시를 생성하고 트랜잭션을 관리하기 때문이다.
✅ 참고
Proxy란?
프록시(Proxy) 는 대리자라는 뜻으로, 클라이언트가 사용하려고하는 실제 대상인 것처럼 위장해서 클라이언트의 요청을 대신 받아주는 역할 을 한다.
프록시는 실제 대상인 것처럼 위장함으로서 이를 사용하는 클라이언트는 구체 클래스를 알 필요가 없어진다.
또한 프록시는 클라이언트의 요청을 받아서 원래 요청 대상에게 바로 넘겨주는 게 아닌, 다양한 부가기능을 추가할 수 있다.
여기서 원래 요청하려는 대상, 즉 최종적으로 요청을 위임받아 처리하는 실제 오브젝트를 Target 이라고 한다.Proxy Pattern이란?
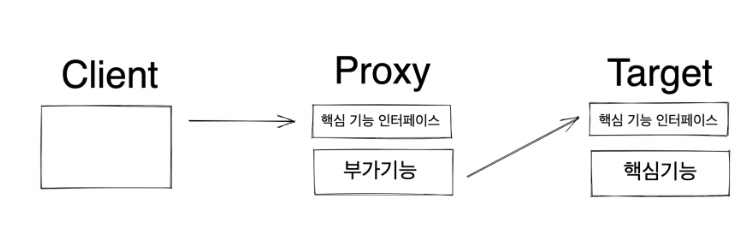
프록시 객체가 객체를 감싸서 Client의 요청을 처리하게 하는 패턴이다.
접근 제어, 부가 기능 추가 등의 이유로 사용된다.
</br>
2.1 프록시 기반 트랜잭션 동작 과정
- 프록시 객체가 생성된다. (Spring이 자동으로 JpaRepository 구현체를 감싼다)
✅ 참고
JpaRepository가 프록시로 감싸지는 과정- JpaRepository를 상속받은 인터페이스를 만들면 Spring이 이를 감지한다.
- Spring은 이 인터페이스의 실제 구현체(SimpleJpaRepository)를 생성한다.
- 이 구현체를 프록시로 감싼다.
- 프록시는
@Transactional이 적용된 메서드를 호출할 때, 트랜잭션을 시작하거나 종료하는 역할을 한다.
- 트랜잭션이 필요한 메서드를 호출하면 프록시가 먼저 실행된다.
- 프록시가 트랜잭션을 시작 한다. (begin)
- PlatformTransactionManager가 트랜잭션을 시작한다.
- 실제 JDBC 커넥션을 가져오면서 setAutoCommit(false)로 설정한다.
- 원래 메서드를 실행한다.
- 정상 종료되면 트랜잭션을 커밋(
commit), 예외가 발생하면 롤백(rollback) 한다.(트랜잭션의 종료)- commit(), rollback() 실행 후, setAutoCommit(true)로 자동적으로 복구된다.
✅ 참고
만약 프록시 없이 @Transactional을 적용한다면?
- 메서드 호출이 원본 객체로 바로 전달되므로 트랜잭션이 적용되지 않는다.
- 예외 발생 시 자동 롤백이 불가능하다.
- 여러 DB 연산이 하나의 트랜잭션으로 묶이지 않는다.
3. 번외) 쿼리메서드 사용시 단순 구체 클래스인 SimpleJpaRepository에 구현된 내용이 없는데 어떻게 동작이 되는걸까?
Spring Data JPA의 쿼리 메서드(Query Method) 기능은 메서드명만으로도 자동으로 Repository 메서드를 생성해 주는 기능이다.
메서드 이름을 분석해서 JPQL을 자동으로 생성하고 실행한다.
//FileMetadataRepository.java
public interface FileMetadataRepository extends JpaRepository<FileMetadata, Long> {
//조회
Optional<FileMetadata> findByCategoryAndReferenceId(FileCategory category, Long referenceId);
}
보통 JpaRepository를 상속받은 커스텀 인터페이스에서 사용하는데, 메서드를 구현하지 않고도 정상적으로 동작하는 이유는 무엇일까?
3.1 쿼리 메서드가 동작하는 방식
-
Spring Data JPA가 프록시(Proxy) 리포지토리를 생성
- 우리가 JpaRepository를 상속하는 인터페이스를 만들면, Spring Data JPA가 이를 자동으로 감지함.
- 그리고 실제 SimpleJpaRepository를 직접 사용하지 않고, 프록시 객체(Proxy)를 생성함.
- 이 프록시 객체가
findByUsername()같은 메서드 호출을 가로채서 내부적으로 동작하게 됨.
-
Method 이름을 분석하여 동적 쿼리 생성 1) 사용자가
findByUsername(String username)을 호출하면, 프록시 객체가 해당 메서드의 이름을 분석함. 2) 메서드 이름을 파싱하여 username이라는 필드 기준으로 WHERE 절이 들어간 쿼리를 생성함. 3) 만약 메서드 이름이findByUsernameAndAge(String username, int age)라면:
-> username과 age 조건을 포함한 WHERE 절을 포함하는 JPQL 쿼리를 동적으로 생성함. -
QueryLookupStrategy를 통해 실행 방식 결정 Spring Data JPA는 QueryLookupStrategy라는 전략을 사용하여 메서드 이름 기반 쿼리 생성 방식을 결정한다.
결정 방식엔 세 가지 방식이 있다.1️⃣ CREATE(기본값) 메서드명을 분석하여 JPQL 쿼리를 동적으로 생성한다.
@Repository public interface UserRepository extends JpaRepository<User, Long> { User findByUsername(String username); }SELECT u FROM User u WHERE u.username = :username이라는 쿼리가 동적으로 생성됨.2️⃣ USE_DECLARED_QUERY
@Query어노테이션이 존재하면 해당 쿼리를 직접 실행한다.@Query("SELECT u FROM User u WHERE u.username = :username") User findByUsername(@Param("username") String username);위처럼 명시적인 JPQL을 사용하면, 쿼리 메서드 이름을 분석하지 않고 직접 실행함.
3️⃣ CREATE_IF_NOT_FOUND
@Query가 있으면 직접 실행하고, 없으면 CREATE 전략처럼 동적 쿼리를 생성함.
3.2 동작하는 이유는 SimpleJpaRepository를 사용하지 않기 때문이다.
우리가 JpaRepository를 상속받아 인터페이스만 정의해도 기본적인 CRUD 기능이 자동으로 동작하는 이유는 Spring Data JPA가 SimpleJpaRepository를 기본 구현체로 사용하기 때문이다.
하지만, 만약 커스텀 인터페이스에 쿼리 메서드를 추가해서 사용하면 이 메서드엔 SimpleJpaRespository가 아닌 다른 매커니즘이 동작하게 된다.
우리가 findByUsername() 같은 쿼리 메서드를 추가했을 때, Spring Data JPA SimpleJpaRepository 내부가 아니라 쿼리 실행 메커니즘을 활용한다.
✅ 쿼리 실행 과정
1.UserRepository.findByUsername("kim")호출
2. Spring Data JPA의 프록시 객체가 가로챔
3. QueryLookupStrategy가 메서드 이름을 분석하여 JPQL 생성
4. EntityManager를 이용해 동적 쿼리를 실행
5. 결과를 반환
❗ 즉, SimpleJpaRepository가 아닌 Spring Data JPA의 쿼리 생성 및 실행 메커니즘이 동작하기 때문에 쿼리메서드가 정상적으로 동작하는 것이다.