

안녕하세요, Kernel360 크루 김찬규 입니다. 오늘 포스팅에서는 WashFit 프로젝트에 배치성 작업을 추가하며 알게된 내용을 바탕으로 스프링 배치에 쉽게 입문 하실 수 있도록 도와드리려고 합니다.
배치
배치 처리는 컴퓨터에서 사람과 상호 작용 없이 이어지는 프로그램(작업) 들의 실행입니다. 당연히 스프링 배치를 사용하지 않더라도 배치성 작업을 처리할 수 있겠죠. 그렇다면 언제 스프링 배치를 사용해야 할까요? 왜 스프링 배치를 사용해야 하나요?
스프링 배치
![]()
Spring Batch 는 기본 일괄 처리 작업을 자동화하며, 일반적으로 오프라인 환경에서 사용자 상호작용 없이 유사한 트랙잭션을 세트로 묶어 처리할 수 있는 기능을 제공합니다 .
그렇다면 언제 배치를 도입해야 할까요? 사용자와의 인터렉션이 포함된 작업이라면 배치로 작업하면 안되겠죠. 또한 단순히 일정에 맞춰 꾸준히 실행되는 작업일 뿐이라면 스케쥴러만 사용하면 됩니다.
사람과 상호작용이 없어도 되는 것은 기본이고, 많은 작업량, 실행 실패에 견디는 견고성, 그리고 이 모든 작업이 실행과 재시도가 자동으로 이루어져야 할 때 배치를 사용해야 합니다.
이를 위해 Spring Batch 는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리에 필수적인 기능을 제공합니다.
개요
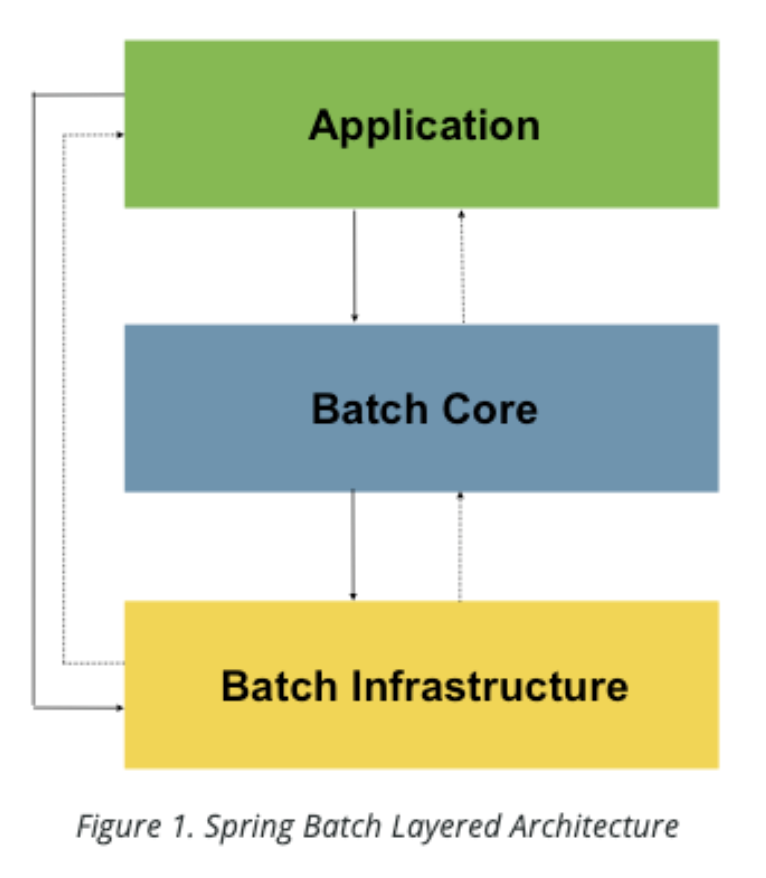
배치의 레이어 구조는 다음과 이미지와 같습니다.
- Application : 개발자가 작성한 모든 배치 작업과 사용자 정의 코드 포함
- Batch Core : 배치 작업을 시작하고 제어하는데 필요한 핵심 런타임 클래스 포함
-
Batch Infrastructure : 개발자와 어플리케이션에서 사용하는 일반적인 Reader 와 Writer 포함
그리고 배치 프로그램은 아래 이미지와 같은 구조로 구현합니다. 대용량의 레코드를 읽고, 작업을 한 후에, 변경사항을 작성하게 되죠.

메타 데이터 테이블
그리고 spring batch 를 활용하기 앞서 배치에 활용할 테이블이 필요합니다. 베치가 성공과 실패에 따라 자동으로 재실행되는 등의 기능을 하기 위해선 메타 데이터를 저장해 놓아야겠죠? 데이터베이스에 따라 다르지만, postgresql 기준으로 6개의 메타 데이터 테이블을 만들어 주어야 합니다.

이 메타 데이터 테이블을 나중에 한번 들여다보면 이렇게 실행 이력을 확인할 수 있습니다. 어떤 작업/스텝에서 실패했는지 성공했는지, 언제 실행되었는지 모두 알 수 있어요.

Spring batch 의존성을 추가하면 이 메타 데이터테이블에 대한 스키마도 전부 제공되니까 너무 걱정마시고 아래 이미지 처럼 검색하셔서 ctrl+c, ctrl+v !! 를 하시면 쉽게 만들어주실 수 있어요.

우리 배치가 달라졌어요.
그리고 하나 더 주의할 점!!
Java 17, Spring Boot 3 버전부터는 Spring Batch 5 를 사용합니다. 이전 버전에 비해서 달라진 점들을 알고 시작해야겠죠? Spring batch 4 버전에서는 동작하던 코드가 Spring batch 5에서는 동작하지 않을 수도 있으니까요. 가장 중요한 두가지만 설명드리자면 다음과 같습니다.
-
다양한 JobParameter Type:
-
JobParameter는 각각의 배치 작업을 고유하게 구분할 수 있도록 해주는 객체인데요, 4.x 버전까지는 4개의 Type(Long, Double, String, Date)만을 지원했지만 5.0부터는 JobParameter 를 커스텀해서 사용할 수 있습니다.
-
-
숨겨진 자동 설정을 명시적으로 변경:
- Job, Step 객체를 쉽게 구성할 수 있도록 도와주는
StepBuilderFactory,JobBuilderFactory가 Deprecated 되었습니다. 이전 4 버전에서는 JobRepository 가 생성되고 설정된다는 내부 동작을 숨기고 있었는데, 이제는 내부에 숨겨져 있었던 JobRepository 를 명시적으로 사용합니다. - 앞으로는
JobRepository를 명시적으로 제공하는 방식을 사용하는 것이 권장됩니다. -
TransactionManager또한 명시적으로 제공하는 방식을 사용하도록 권장됩니다.
- Job, Step 객체를 쉽게 구성할 수 있도록 도와주는
이제 차례대로 Spring batch 를 구성하는 객체들을 소개하겠습니다.
Job
Job 은 배치처리 과정을 하나의 단위로 만들어 놓은 객체입니다. 또한 배치처리 과정에 있어 전체 계층 최상단에 위치하고 있습니다. 쉽게 설명하여 실행할 작업의 설계도입니다.

JobInstance
Job의 실행의 단위를 나타냅니다. Job을 실행시키게 되면 하나의 JobInstance가 생성되게 됩니다.
예를들어 1월 1일 실행, 1월 2일 실행을 하게 되면 각각의 JobInstance가 생성되며 1월 1일 실행한 JobInstance가 실패하여 다시 실행을 시키더라도 이 JobInstance는 1월 1일에 대한 데이터만 처리하게 됩니다.
JobExecution
JobExecution은 JobInstance에 대한 실행 시도에 대한 객체입니다.
1월 1일에 실행한 JobInstacne가 실패하여 재실행을 하여도 동일한 JobInstance를 실행시키지만 이 2번에 실행에 대한 JobExecution은 개별로 생기게 됩니다.
JobExecution은 이러한 JobInstance 실행에 대한 상태,시작시간, 종료시간, 생성시간 등의 정보를 담고 있습니다.
JobParameter
JobInstance는 Job의 실행 단위라고 했습니다. 그렇다면 JonInstance 는 어떻게 구별 할까요? 바로 JobParameters 객체로 구분하게 됩니다.
JobParameters 객체는 배치 작업을 시작하는 데 사용되는 일련의 매개 변수입니다. 이를 통해 각 JobInstance를 구별하죠.
"JobInstance = Job + 식별 JobParameters"
JobParameters는 JobInstance 구별 외에도 JobInstacne에 전달되는 매개변수 역할도 하고 있습니다. JobParameters는 원래 String, Double, Long, Date 4가지 형식만을 지원하고 있었지만, 버전업이 되면서 커스텀이 가능해지게 되었습니다.
JobRepository
JobRepository는 Spring Batch의 핵심 구성 요소 중 하나로, 배치 작업(Job)의 메타데이터와 실행 상태를 관리하는 영속성 매커니즘을 제공합니다. 이 Repository는 다양한 스테레오타입(예: Job, Step)에 대한 CRUD(Create, Read, Update, Delete) 작업을 수행합니다.
기본적으로 JobRepository는 데이터베이스를 사용하여 Job과 관련된 정보를 저장하며, 이 정보는 실패한 Job의 재시작이나 실행 상태의 추적 및 모니터링에 사용됩니다.
주요 역할과 특징은 다음과 같습니다:
-
CRUD Operations:
-
JobRepository는 배치 작업과 관련된 데이터를 데이터베이스에 CRUD 작업을 통해 관리합니다. Job, Step, 그리고 관련된 실행 상태 등이 이 Repository를 통해 저장 및 검색됩니다.
-
-
JobExecution:
- Job이 처음 시작될 때,
JobRepository에서는JobExecution이 생성되고 반환됩니다.JobExecution은 해당 Job의 한 번의 실행을 나타냅니다. Job의 실행이 완료되면 해당JobExecution에 대한 정보가 Repository에 저장됩니다.
- Job이 처음 시작될 때,
-
StepExecution:
- 배치 작업은 하나 이상의 Step으로 이루어져 있습니다. 각각의 Step은
StepExecution을 가지며, 이는 Step의 한 번의 실행을 나타냅니다.StepExecution역시JobRepository에 의해 저장되어 실행 상태를 추적합니다.
- 배치 작업은 하나 이상의 Step으로 이루어져 있습니다. 각각의 Step은
-
Persistence of Job Metadata:
-
JobRepository는 Job과 Step의 메타데이터를 저장함으로써, Job이나 Step의 상태, 실행 횟수, 실행 시간 등의 정보를 계속 추적할 수 있습니다.
-
-
Transaction Management:
- 배치 작업에서는 데이터의 일관성을 유지하기 위해 트랜잭션 관리가 필요합니다.
JobRepository는 내부적으로 트랜잭션을 사용하여 Job과 Step의 상태를 안전하게 관리합니다.
- 배치 작업에서는 데이터의 일관성을 유지하기 위해 트랜잭션 관리가 필요합니다.
간단히 말하면, JobRepository는 배치 작업의 메타데이터와 실행 상태를 데이터베이스에 영속적으로 저장하고, 작업의 실행 및 추적을 관리하는 중요한 역할을 수행합니다.
Step

배치 작업의 독립적이고 연속적인 단계를 캡슐화하는 객체입니다.
Job은 하나 이상의 Step으로 이루어집니다. Step은 실제 배치 처리를 정의하고 제어하는 데 필요한 모든 정보를 포함하며, Job과 마찬가지로 고유한 JobExecution과 관련된 개별 StepExecution을 갖습니다.
-
ItemReader:
-
ItemReader는 데이터를 읽어오는 역할을 합니다. 다양한 소스에서 데이터를 읽어올 수 있으며, 파일, 데이터베이스, 메시지 큐 등에서 데이터를 읽어올 수 있습니다.ItemReader는 읽어온 데이터를ItemProcessor로 전달합니다.
-
-
ItemProcessor:
-
ItemProcessor는 읽어온 데이터를 가공하거나 필터링하는 역할을 합니다. 데이터의 변환, 유효성 검사, 비즈니스 로직 적용 등을 수행할 수 있습니다.ItemProcessor는 선택적으로 사용할 수 있으며, 필요에 따라 생략할 수도 있습니다. 처리된 데이터는ItemWriter로 전달됩니다.
-
-
ItemWriter:
-
ItemWriter는 가공된 데이터를 저장하거나 외부 시스템으로 출력하는 역할을 합니다. 다양한 형식으로의 출력이 가능하며, 파일, 데이터베이스, 메시지 큐 등으로 데이터를 쓸 수 있습니다.ItemWriter는 읽어온 데이터를 최종적으로 저장하거나 다른 시스템으로 전송하는 역할을 합니다.
-
-
StepExecution:
- 각 Step은 실행될 때
StepExecution이 생성되고JobRepository에 의해 관리됩니다.StepExecution은 Step의 실행 상태를 나타내며, 트랜잭션 관리와 함께 실행 상태를 안전하게 저장합니다. -
JobExecution과 유사하지만 스텝이 실행되지 못하고 이전 스텝이 실패하면 해당StepExecution은 저장되지 않습니다. (즉, StepExecution은 실제로 시작될 때만 생성)
- 각 Step은 실행될 때
-
Commit과 Rollback:
-
Step은 여러 개의Chunk로 나누어져 있을 수 있습니다. 각Chunk는ItemReader로부터 읽어온 데이터를ItemProcessor와 함께 처리한 후,ItemWriter로 쓰는 단위입니다. 각 Chunk의 처리가 성공하면 해당 Chunk에 대한 변경 내용이 커밋되고, 실패하면 롤백됩니다.
-
-
Listeners:
-
Step은 실행 전, 실행 후, 실패 시 등의 이벤트에 대한 리스너를 등록할 수 있습니다. 이를 통해Step의 실행 중에 추가적인 로직을 수행할 수 있습니다.
-
간단히 말하면, Step은 배치 작업을 단계적으로 처리하기 위한 구성 요소로서, 읽기, 가공하기, 쓰기의 세 가지 핵심 작업을 포함하고 있습니다.
실행중 장애 처리
StepBuilder 는 실행 중에 발생한 장애에 대하여 어떻게 처리할 것인지 결정하도록 도와주는 설정을 제공합니다
이러한 기능을 통해 실행 중에 발생하는 장애나 오류를 다룰 수 있습니다.
-
Skip:
-
Skip은 특정 예외가 발생했을 때 해당 청크의 처리를 건너뛰도록 하는 기능입니다. 일부 데이터가 처리되지 않더라도 배치 작업이 중단되지 않고 계속 진행됩니다. -
Skip기능을 사용하려면skip-limit를 설정하여 몇 번의 예외가 발생했을 때 스킵할 것인지를 지정해야 합니다. -
SkipListener를 통해 스킵이 발생했을 때 추가적인 로직을 수행할 수 있습니다.
-
-
Retry:
-
Retry는 예외가 발생했을 때 해당 청크를 재시도하는 기능입니다. 특정 예외가 발생하면 지정된 횟수만큼 재시도를 시도합니다. -
RetryListener를 통해 재시도 전, 후에 추가적인 로직을 수행할 수 있습니다.
정리
정리하자면, 스프링 배치를 어플리케이션 개발에 무조건 사용해야할 필요는 없지만, 만약 사용하게 된다면 스프링 배치는 대용량의 데이터를 효율적으로 처리하고 관리해줄 수 있는 강력한 도구가 되어줄 것입니다.
배치 처리를 위해 일련의 작업을 자동화하고, 대용량 레코드를 효율적으로 읽고 쓰며, 실행 중에 발생할 수 있는 장애를 관리할 수 있습니다.
거기에 더해서 로깅, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등과 같은 다양한 기능을 활용할 수 있습니다.