

안녕하세요 커널360 1기 크루 우무룡입니다.
//Scanner
Scanner sc = new Scanner(System.in);
//BufferedReader
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
백준에서 코딩테스트 문제를 푼 경험이 있으시다면 위와 같이 객체를 생성해서 입출력을 다뤄보셨을 것 입니다. 흔히 기본 문법을 배울때 배우는 Scanner를 사용하다가 자연스레 BufferedReader에 대해서도 알게됩니다.
두 클래스 모두 표준입력으로 부터 입력을 받아오는 역할은 같으나, 인스턴스화 하는 형태뿐만 아니라 성능에서도 차이가 있습니다. 처음엔 문제를 푸는데에 집중하느라 왜 또는 언제 BufferedReader를 사용해야 하는지, 어떻게 입력이 이루어지는지 알지 못하고 넘어가는 경우가 많습니다. 이 글에서 아래 두 가지에 대해 다뤄보겠습니다.
- 두 클래스를 인스턴스화 할때 공통으로 사용하는 System.in, InputStreamReader의 역할
- Scanner와 BufferedReader의 성능 차이와 이유
System.in 과 InputStream
System.in 과 InputStream에 대해 알기 전에 우선 Stream에 대한 이해가 필요합니다.
스트림이란?
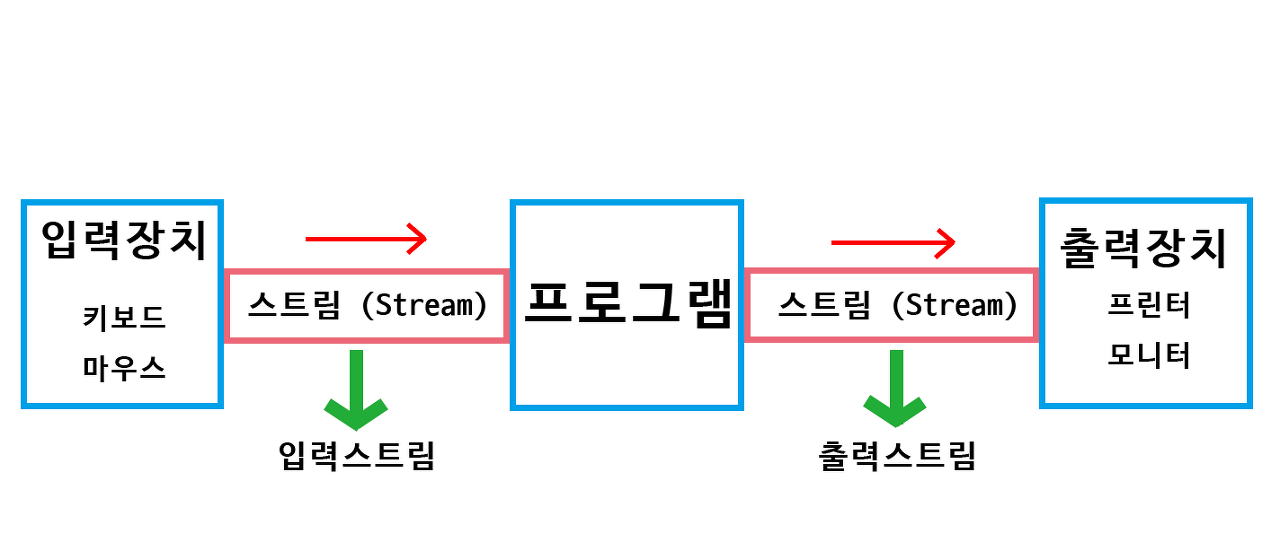 자바에서 모든 입출력은 스트림을 통해 이루어집니다. 위 그림에서처럼 스트림은 입출력 소스와 프로그램 사이 데이터 흐름의 중간 매개역할을 하는 가상통로라고 할 수 있습니다.
자바에서는 이러한 데이터의 흐름을 쉽고 효율적으로 다루기 위해 데이터를 읽어들이려는 source와 데이터를 쓰려는 target에 따라 각각 다른 스트림 클래스들을 제공합니다.
자바에서 모든 입출력은 스트림을 통해 이루어집니다. 위 그림에서처럼 스트림은 입출력 소스와 프로그램 사이 데이터 흐름의 중간 매개역할을 하는 가상통로라고 할 수 있습니다.
자바에서는 이러한 데이터의 흐름을 쉽고 효율적으로 다루기 위해 데이터를 읽어들이려는 source와 데이터를 쓰려는 target에 따라 각각 다른 스트림 클래스들을 제공합니다.
스트림의 분류
java.io 패키지에서 워낙 다양한 클래스들과 인터페이스를 제공 하기에 모두 알기는 어렵습니다. 크게 클래스명을 기반으로 아래와 같이 구분해 볼 수 있습니다.
- InputStream: 바이트 기반의 입력 스트림의 최상위 추상 클래스
- OutputStream: 바이트 기반의 출력 스트림의 최상위 추상 클래스
- Reader: 문자 기반의 입력 스트림의 최상위 추상 클래스
- Writer: 문자 기반의 출력 스트림의 최상위 추상 클래스
위 클래스들을 상속받아 구현된 여러 하위 클래스들을 통해 다양한 소스로부터 데이터를 읽고 쓸 수 있습니다. 해당 클래스를 상속한 클래스들은 대부분 위 최상위 클래스명을 포함하고 있습니다. 그래서 위 최상위 추상클래스를 알고계신다면 처음보는 클래스를 보더라도 이름을 통해 대략 어떤 역할을 하는지 유추해볼 수 있을 것 입니다.
그래서 System.in은?
스트림에 대해 알아보면서 InputStream은 바이트 기반 입력 스트림의 최상위 추상클래스라는 것을 알게되었습니다.
스트림에 대한 이해가 선행되어야 했던 이유는 바로 System.in이 InputStream 타입의 필드이기 때문입니다.
 실제 System 클래스를 살펴보면 위와 같이 in이 InputStream 타입으로 된 정적필드 라는 걸 볼 수 있습니다.
System.in은 ‘표준 입력 스트림’입니다. 사용자가 프로그램에게 전달(일반적으로 콘솔이나 터미널 등을 통한 키보드 입력)하는 데이터들이 System.in을 통해 전달된다는 의미입니다.
실제 System 클래스를 살펴보면 위와 같이 in이 InputStream 타입으로 된 정적필드 라는 걸 볼 수 있습니다.
System.in은 ‘표준 입력 스트림’입니다. 사용자가 프로그램에게 전달(일반적으로 콘솔이나 터미널 등을 통한 키보드 입력)하는 데이터들이 System.in을 통해 전달된다는 의미입니다.
Scanner나 BufferedReader를 사용하지 않더라도 InputStream만으로도 입력이 가능합니다. 아래와 같이 InputStream의 read() 메서드를 사용하면 입력할 수 있습니다.
import java.io.IOException;
import java.io.InputStream;
public class Input_Test {
public static void main(String[] args) throws IOException {
InputStream inputstream = System.in;
byte[] a = new byte[10];
inputstream.read(a);
for(byte val : a){
System.out.println(val);
}
}
}
그러나 위 코드를 실행해서 임의로 입력한 값을 출력해보면, 입력한 값과는 다른 값이 출력되는 걸 확인할 수 있습니다. 그것은 InputStream이 바이트 단위로 데이터를 주고받는 바이트 스트림이기 때문입니다. 어떤 값을 입력하더라도 InputStream.read()는 해당 입력값에서 1바이트만 읽어들이고, 나머지 데이터는 스트림에 남아있게 됩니다.
바이트 단위만으로는 데이터를 다루는데 한계가 있습니다. 가까운 예시로, 한글을 인식할 수 없습니다. UTF-8 인코딩을 예로 들면, 한글은 3byte를 사용합니다. ‘가’라는 문자는 각 1Byte 씩 234, 176, 128 의 구성으로 합쳐져 ‘가’라고 표현됩니다. InputStream.read() 는 1 Byte 밖에 못 읽기 때문에 가장 앞의 1 Byte인 234 까지만 읽고 나머지는 바이트 스트림에 남아있게 됩니다.
1바이트로 표현가능한 문자의 범위인 확장 아스키코드
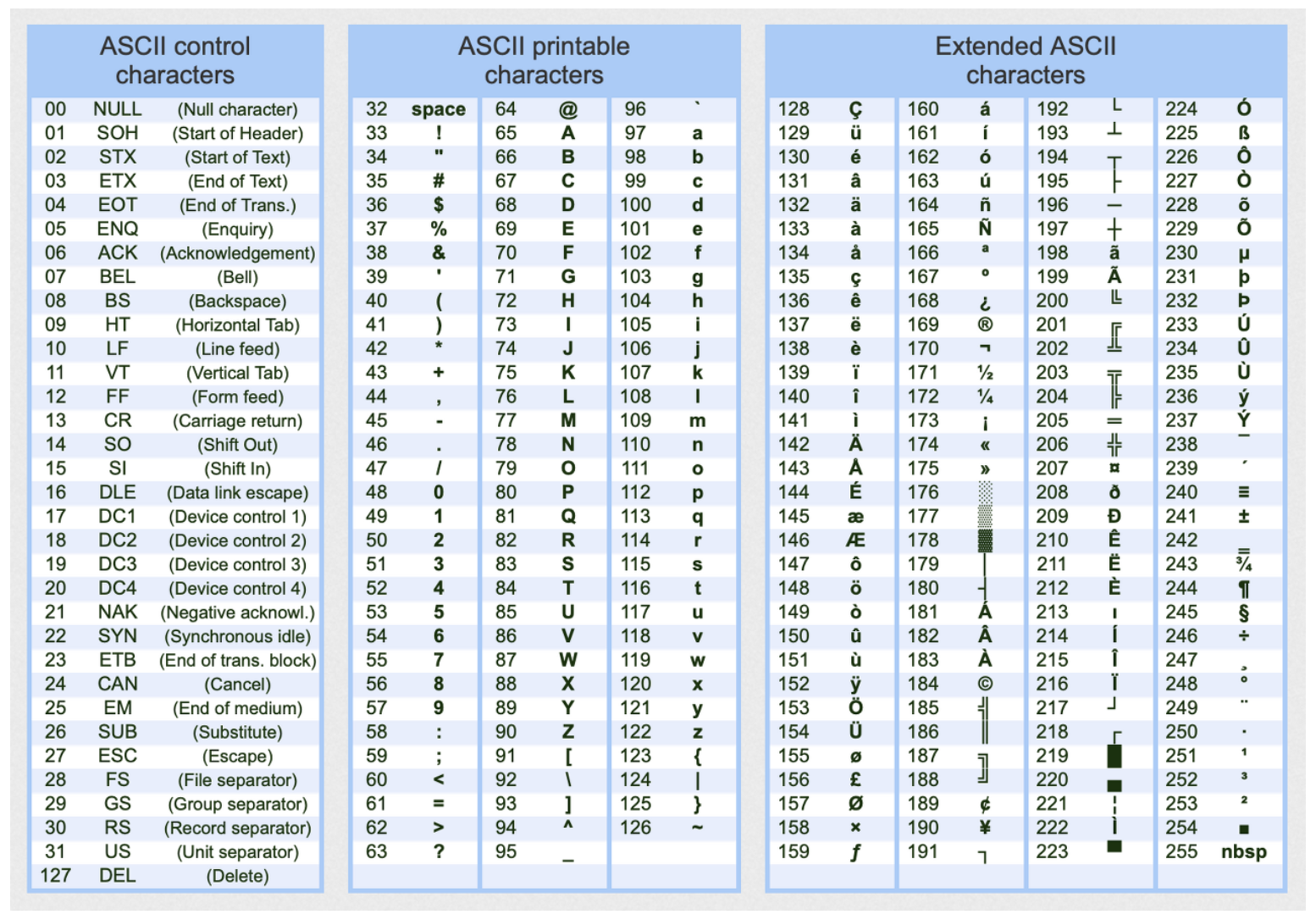
2바이트 이상으로 구성된 데이터들도 우리가 원하는 문자형식으로 다룰수 있어야 합니다. 그 역할을 하는 클래스가 InputStreamReader 입니다.
InputStreamReader
 InputStreamReader는 Java에서 바이트 스트림(InputStream)을 문자 스트림으로 변환하는 데 사용되는 클래스입니다. InputStream이 바이트 단위로 읽어들이는 데이터를
문자단위 데이터로 변환하는 중개자 역할을 합니다. 다양한 인코딩 방식을 지원하고, 특정 인코딩에 맞는 문자 데이터로 변환할 수 있습니다.
바이트 데이터를 문자 단위로 변환하는 것은 Charset이라는 클래스에서 담당합니다. 이러한 InputStreamReader를 문자 스트림이라고 구분할 수 있습니다.
InputStreamReader는 Java에서 바이트 스트림(InputStream)을 문자 스트림으로 변환하는 데 사용되는 클래스입니다. InputStream이 바이트 단위로 읽어들이는 데이터를
문자단위 데이터로 변환하는 중개자 역할을 합니다. 다양한 인코딩 방식을 지원하고, 특정 인코딩에 맞는 문자 데이터로 변환할 수 있습니다.
바이트 데이터를 문자 단위로 변환하는 것은 Charset이라는 클래스에서 담당합니다. 이러한 InputStreamReader를 문자 스트림이라고 구분할 수 있습니다.
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class Input_Test {
public static void main(String[] args) throws IOException {
InputStream inputstream = System.in;
InputStreamReader sr = new InputStreamReader(inputstream);
int c = sr.read();
System.out.println((char)c);
}
}
위 코드처럼 System.in을 InputStream으로 감싼뒤에 실행해 입력을 전달할 수 있습니다. 실행해보시면 이번에는 한글을 입력하더라도 입력한 값이 정확히 나오는 걸 확인해 보실 수 있습니다.
//Scanner
Scanner sc = new Scanner(System.in);
//BufferedReader
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
이쯤에서 이런 의문이 들 수 있습니다. 입력을 받기 위해 객체를 생성하는 위 코드를 다시 살펴보면, BufferedReader 인스턴스를 생성 할때는 InputStreamReader를 사용하는데 Scanner는 사용하지 않는 것 처럼 보입니다. Scanner는 그럼 바이트 데이터를 어떻게 문자 데이터로 취급하는걸까요?
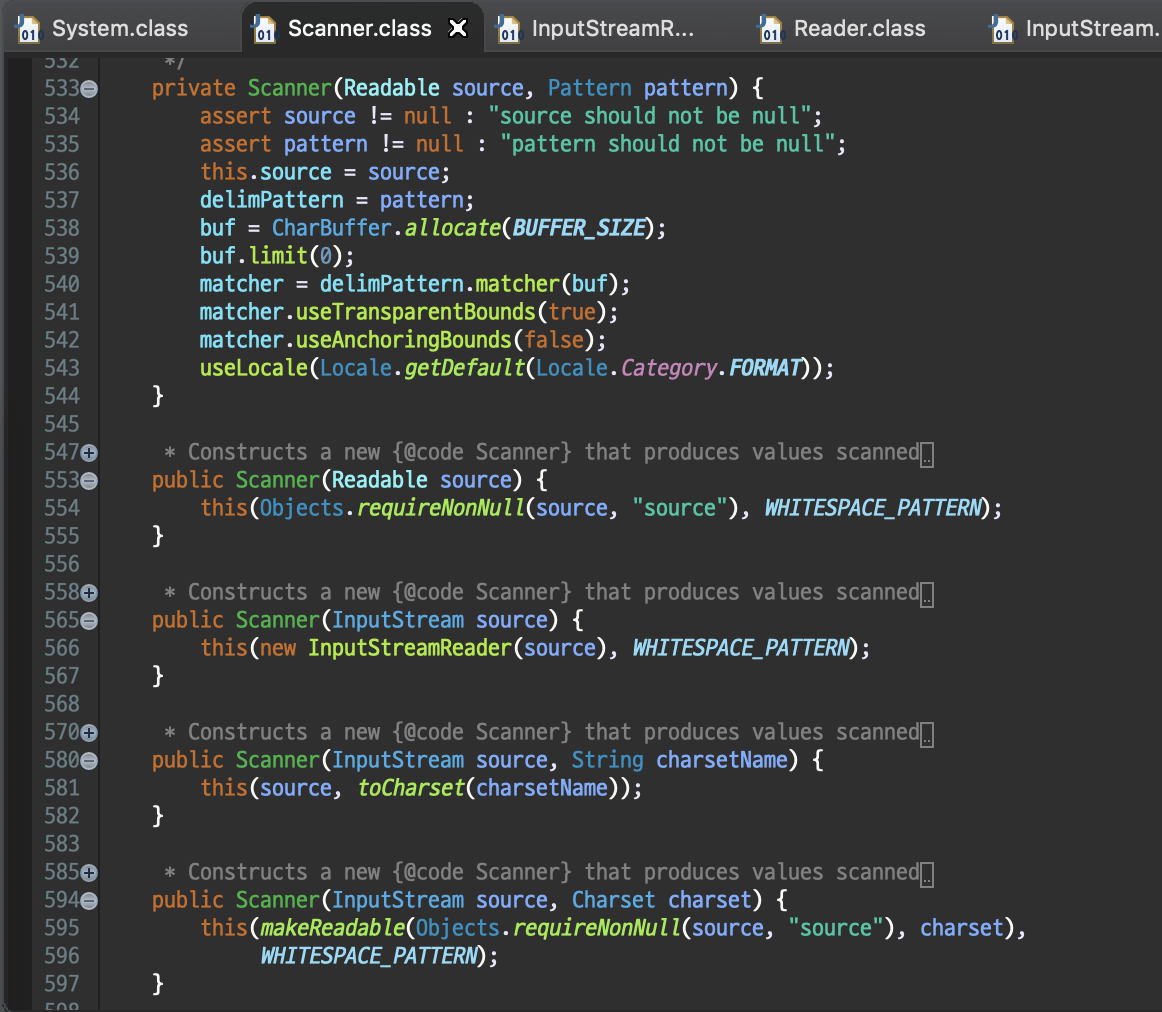 위 캡처와 같이 Scanner 클래스 내부의 생성자를 살펴보면 알 수 있습니다. 여러가지 생성자가 오버로딩 되어있는데 살펴보면 모두 최상단의
위 캡처와 같이 Scanner 클래스 내부의 생성자를 살펴보면 알 수 있습니다. 여러가지 생성자가 오버로딩 되어있는데 살펴보면 모두 최상단의
private Scanner(Readable source, Pattern pattern)로 보내지고 있습니다.
우리가 Scanner sc = new Scanner(System.in);이렇게 사용하면 아래의 생성자를 호출하게 됩니다.
public Scanner(InputStream source) {
this(new InputStreamReader(source), WHITESPACE_PATTERN);
}
최상단의 생성자를 호출하면서 InputStream인 source를 InputStreamReader로 감싸서 전달하고 있습니다. 결국 Scanner도 내부적으로 InputStreamReader를 활용해서 문자를 다루고 있는 것 입니다.
BufferedReader
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
이제 InputStreamReader의 역할을 알았으니 위 코드를 다시 보면 다음 두 가지를 유추해 볼 수 있습니다.
- 바이트 스트림인 InputStream을 통해 바이트 단위로 데이터를 입력 받는다
- 바이트 데이터를 문자 형태로 다루기 위해 문자 스트림인 InputStream으로 감싼다.
그럼 이제 BufferedReader의 역할이 뭔지에 대한 답이 필요합니다.
앞서 InputStreamReader는 문자 스트림으로 데이터를 ‘문자’ 형태로 다룰 수 있다고 했습니다.
BufferedReader는 문자를 문자열 단위로 다룰수 있도록 하는 역할을 합니다.
내부적으로 Buffer라는 메모리 공간을 사용하여 입력받은 문자를 쌓아둔 뒤 (버퍼가 가득 차거나, 개행 문자가 나타나면)한 번에 문자열처럼 보내는 것 입니다. readLine() 메서드를 활용하면 소스로 부터 개행문자를 만나기 전까지 한 줄 전체를 String 타입으로 리턴받을 수 있습니다. BufferedReader를 사용하지 않는다면 매번 직접 char 배열을 선언하고 관리하는 불편함을 겪어야 할 것 입니다.
Scanner와의 차이
Scanner도 nextLine() 메서드를 사용하면 문자열을 다룰 수 있습니다. 버퍼의 크기나 기능에 차이는 있지만, Scanner 또한 내부적으로 버퍼를 사용하기 때문입니다. Scanner의 버퍼 크기는 1kb이고, BufferedReader는 8kb(디폴트)이며 버퍼 크기 조절 기능을 제공합니다.
버퍼의 크기와 기능보다 더욱 중요한 차이점이 있습니다. Scanner가 정수형 입력을 받는 nextInt() 메서드를 살펴보겠습니다.
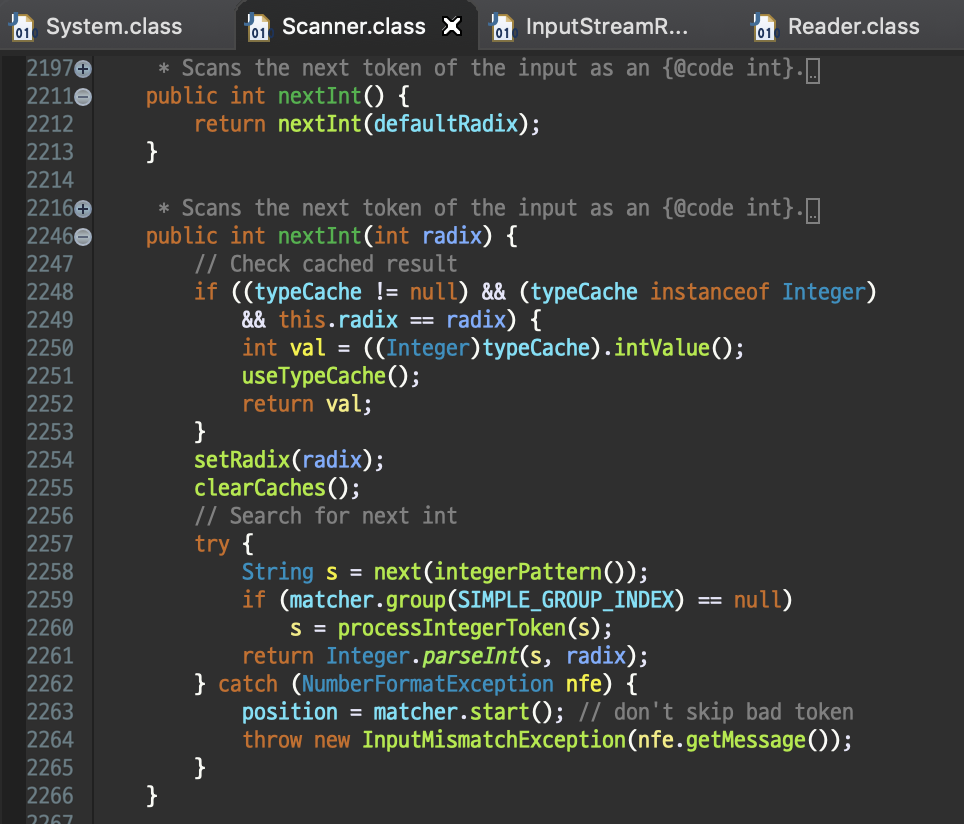 Scanner.nextInt()를 사용하면 오버로딩된 아래의 메서드로 보내집니다. 눈여겨 봐야할 것은 try-catch문의
Scanner.nextInt()를 사용하면 오버로딩된 아래의 메서드로 보내집니다. 눈여겨 봐야할 것은 try-catch문의 String s = next(integerPattern());입니다.
integerPattern()메서드를 따라가보면 buildIntegerPatternString()메서드를 포함하고 있습니다. 해당 메서드는 아래와 같이 많고 복잡한 정규식을 만들어 반환합니다.
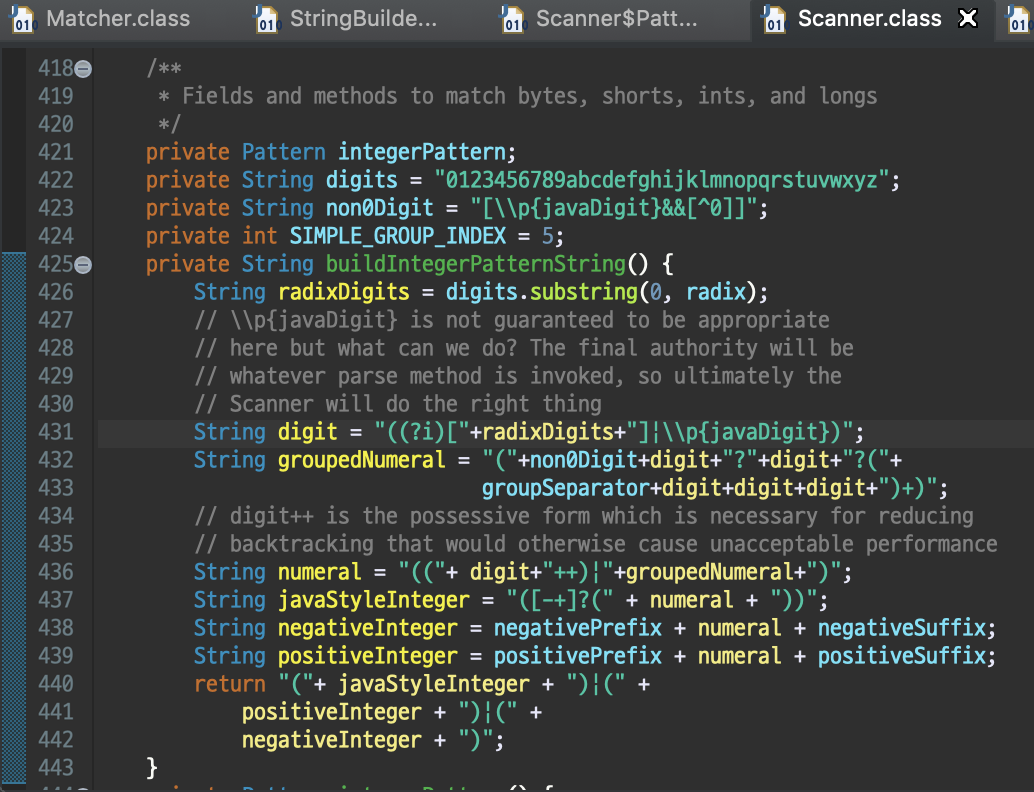 정규식을 반환하면 next 메서드에서 입력값이 해당 정규식에 맞는지 검사하게 됩니다. BuffererdReader와의 주요한 차이점이 바로 이 점입니다.
Scanner는 입력값에 대해 강력한 정규식 검사를 하는 반면, BufferedReader는 별도의 정규식 검사를 수행하지 않습니다. 그렇기에 성능상으로는 BufferedReader가 더 우세합니다.
반대로 Scanner는 여러 예외적인 입력값에 대해서도 특정 타입으로 변환할 수 있는지 정확하게 파악할 수 있습니다. 즉, 타입 변환의 안전성이 뛰어납니다.
정규식을 반환하면 next 메서드에서 입력값이 해당 정규식에 맞는지 검사하게 됩니다. BuffererdReader와의 주요한 차이점이 바로 이 점입니다.
Scanner는 입력값에 대해 강력한 정규식 검사를 하는 반면, BufferedReader는 별도의 정규식 검사를 수행하지 않습니다. 그렇기에 성능상으로는 BufferedReader가 더 우세합니다.
반대로 Scanner는 여러 예외적인 입력값에 대해서도 특정 타입으로 변환할 수 있는지 정확하게 파악할 수 있습니다. 즉, 타입 변환의 안전성이 뛰어납니다.
성능차이는 얼마나?
BufferedReader의 성능이 더 우세하다고 했는데요, 실제로 얼마나 더 우세할 지 알면 좋을 것 같습니다. 백준 사이트에서 여러가지 언어와 입력 방법별로 측정된 내용을 참조했습니다.
10,000이하의 정수 10,000,000개가 적힌 파일을 입력받는데 걸린 시간을 10번 측정한 뒤, 평균값으로 순위를 매긴 내용입니다.
 총 25가지 항목이 있는데 BufferedReader는 0.65초로 전체중 6위, Scanner는 4.8초로 17위를 차지했습니다.
BufferedReader가 Scanner에 비해 약 7.5배 빠른 수치입니다. BufferedReader가 C언어의 scanf보다 빠른 점이 눈에 띕니다.
총 25가지 항목이 있는데 BufferedReader는 0.65초로 전체중 6위, Scanner는 4.8초로 17위를 차지했습니다.
BufferedReader가 Scanner에 비해 약 7.5배 빠른 수치입니다. BufferedReader가 C언어의 scanf보다 빠른 점이 눈에 띕니다.
마무리
시작할 때 다루기로 한 아래 두 가지 항목에 대해 정리하며 마무리 하겠습니다.
- 두 클래스를 인스턴스화 할때 공통으로 사용하는 System.in, InputStreamReader의 역할
-
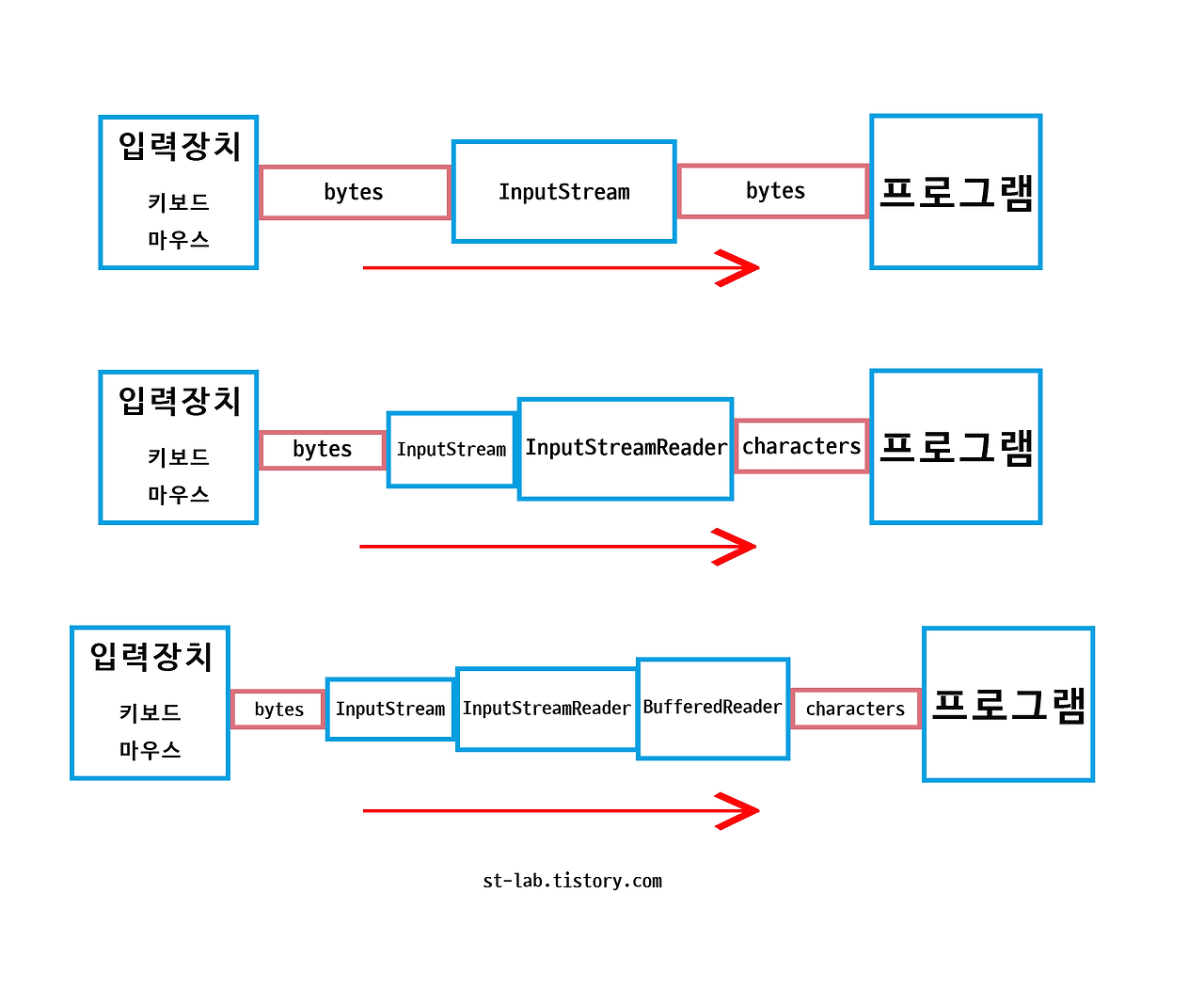
- InputStream은 바이트 단위로 데이터를 읽어들이는 바이트 스트림입니다. System.in의 타입이 InputStream입니다.
- InputStreamReader는 바이트 데이터를 문자 단위로 처리할 수 있도록 중개하는 역할을 합니다.
- Scanner와 BufferedReader의 성능 차이와 이유
- BufferedReader는 버퍼를 사용해서 문자 데이터를 문자열로 다룰 수 있게 하는 역할을 합니다. 별도 정규식 검사를 하지 않습니다.
- Scanner는 입력받은 값에 대해 내부적으로 정규식 검사를 수행하여 타입 안전성이 뛰어납니다.
- BufferedReader가 Scanner에 비해 약 7.5배 빠릅니다. (정수 10,000,000개가 적힌 파일 입력 기준)
마지막으로, 자바로 알고리즘 문제를 푸는 경우에는 굳이 Scanner를 사용할 필요가 없습니다. 문제에서 예외적인 입력이 아닌 조건에 맞는 정해진 입력이 주어지기 때문입니다. 입력의 수가 많지 않고 시간제한이 충분한 경우에는 Scanner를 사용해도 무방하겠지만 일반적으로 성능이 중요하기 때문에 BufferedReader를 사용하시는 걸 권장합니다.
참고 출처 :
https://st-lab.tistory.com/41 [st-lab:티스토리]
https://www.acmicpc.net/blog/view/56 [BOJ]
https://www.tcpschool.com/java/java_io_stream [TCPSCHOOL]